Mở đầu
Tiếp tục những bài viết về MySQL Clusters, trong bài viết này mình sẽ cùng các bạn tìm hiểu bản chất và cách thức hoạt động của 1 MySQL Clusters cơ bản. Có rất nhiều các mô hình hoạt động của MySQL ví dụ như: Master-Slave, Master-Master (Galera), Cluster,... Tuy nhiên theo mình thấy thì MySQL Cluster mang lại các lợi ích toàn diện và đầy đủ nhất.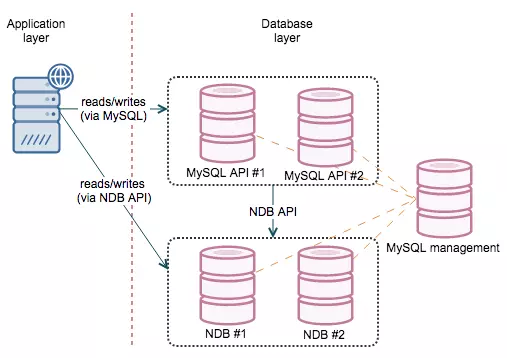
Tổng quan MySQL Cluster
Theo định nghĩa từ trang chủ MySQL thì:
MySQL Cluster là một cơ sở dữ liệu phân tán được thiết kế cho việc mở rộng và tính sẵn sàng cao. Nó cung cấp khả năng truy cập thời gian thực trong bộ nhớ với tính nhất quán giao dịch trên các phân vùng và bộ dữ liệu phân tán. Nó được thiết kế cho các ứng dụng quan trọng.
Hiểu cơ bản MySQL có các chức năng:
-
Khả năng mở rộng (scalability) cao
-
Khả năng sẵn sàng uptime (availability) 99,999%
-
Bảo toàn dữ liệu với khả năng sao lưu giữa các node.
-
....
Các thành phần của 1 MySQL Cluster
Data Node:
Data node với vai trò chính là lưu trữ các dữ liệu theo phân vùng của cả cluster, vì cluster có tính phân tán và sao lưu lẫn nhau nên số Data node luôn ít nhất từ 2 nodes trở lên thì mới phát huy tác dụng của MySQL Cluster. Trên các data node này, dữ liệu sẽ được cắt nhỏ ra thành các phân vùng dữ liệu và các phân vùng này sẽ có các bản sao chính và bản sao phụ. Còn về cách chia các phân vùng (partition) và số bản sao (replica) sẽ được nói trong phần sau của bài viết. Service được chạy trên Data Node có tên ndbd.
SQL Node
SQL Node với vai trò nhận các câu lệnh SQL query từ phần application gửi xuống, từ đó thông qua API với các cổng và giao thức riêng (NDB API) để gửi câu lệnh đến Data Node lấy dữ liệu và trả ngược về cho ứng dụng hoặc người dùng. Service chạy trên SQL Node là mysqld.
Management Node
Management Node chịu trách nhiệm quản lý các SQL Node và Data Node, quản lý ở đây với các việc như khởi tạo node mới, restart node, backup dữ liệu giữa các node, phân chia Node Group (mình sẽ giải thích phần sau),... Khi một Cluster đã hoạt động ổn định thì Node management mang ý nghĩa đứng giám sát bên ngoài nên nếu Node Management có down thì cluster vẫn hoạt động bình thường. Tất nhiên là lúc đó sẽ không thể quản lý bao gồm: thêm, xóa, sửa node trong cluster.
Khái niệm về Node Group, Partition, Replica.
Replica - Bản sao
Trong khi cài đặt MySQL cluster các bạn sẽ phải cấu hình một thông số đó là số bản sao cho 1 phân vùng dữ liệu ở trong cluster, thường giá trị này sẽ là 2. Số bản sao này sẽ ảnh hưởng trực tiếp đến số Node Group. Số bản sao càng cao thì tính toàn vẹn dữ liệu và độ sẵn sàng càng cao, tuy nhiên cái gì cũng có mặt trái, số bản sao nhiều thì sẽ cần nhiều node để lưu dữ liệu hơn.
Node Group
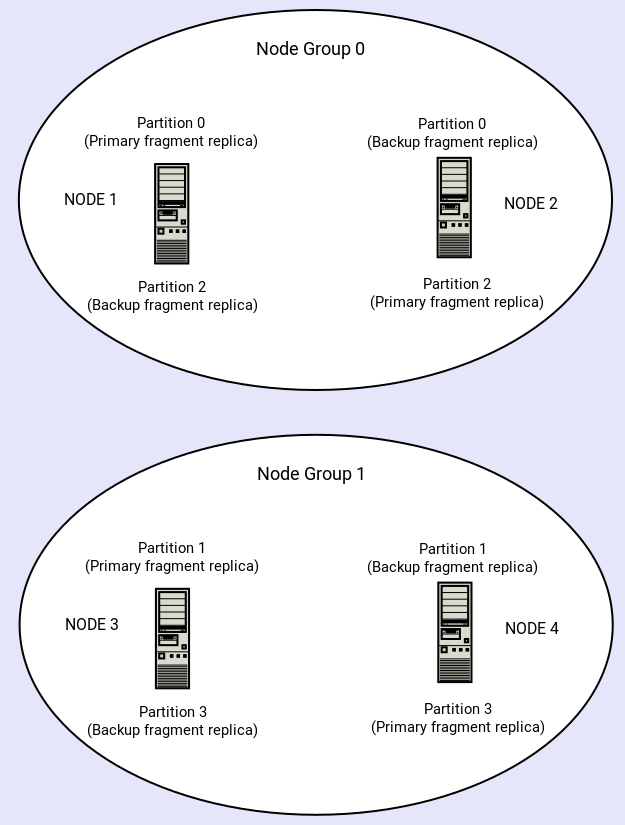
Số Node group được tính bằng công thức Số Node Group = Số Data Node / số bản sao trong một trường hợp cơ bản (hình trên) với 2x2 data node và 2 bản sao cho mỗi phân vùng thì ta sẽ có 2 Node Group. Các data node trong 1 node group sẽ lưu các dữ liệu giống nhau.
Partition - Phân vùng
Dữ liệu của bạn sẽ không được lưu toàn bộ trên bất cứ 1 node nào cả mà nó sẽ được chia thành các phân vùng nhỏ hơn. Số phân vùng sẽ được tính bằng công thức Số phân vùng = Số Data node * số luồng LDM
Khi sử dụng với Engine là Ndbd mặc định thì số luồng LDM tại mỗi node sẽ là 1 nên => Số phân vùng = Số Data node
Với ví dụ trên ta thấy:
-
Node Group 0 gồm: Node 1 và Node 2
-
Node 1 chứa phân vùng 0 (phân vùng chính) và phân vùng 2 (phân vùng phụ)
-
Node 2 chứa phân vùng 0 (phân vùng phụ) và phân vùng 2 (phân vùng chính)
-
Node Group 1 gồm: Node 3 và Node 4
-
Node 3 chứa phân vùng 1 (phân vùng chính) và phân vùng 3 (phân vùng phụ)
-
Node 4 chứa phân vùng 1 (phân vùng phụ) và phân vùng 3 (phân vùng chính)
Với các chia phân vùng dữ liệu như bên trên thì khi cluster vẫn hoạt động bình thường khi chỉ cần 1 node duy nhất trong các Node Group hoạt động. Điều này giúp đảm bảo tính sẵn sàng dữ liệu của Cluster.
Thử nghiệm
-
Nếu management node down thì cluster có sao không? Không sao nếu cluster đang hoạt động bình thường
-
Nếu có một node bất kỳ bị down thì cluster có down theo không? Chỉ cần duy nhất 1 node trong mỗi node group còn up thì cluster vẫn hoạt động bình thường.
-
Nếu số node up không đủ để hoàn thiện database thì thế nào? Hệ thống sẽ tự nhận thấy việc này và gửi lệnh ngắt toàn bộ data node để bảo toàn dữ liệu.
-
Nếu giờ tôi bật node 1 và node 3 ghi thêm dữ liệu vào rồi tắt đi, bật lên node 2 và node 4 thì dữ liệu có bị sai đi không? Cluster sẽ phát hiện ra sự sai lệnh này (có thể bằng trường timestamp) và không cho phép 2 node này được hoạt động.
Kết
Ngoài ra bạn có thể đọc thêm về các lỗi thường gặp trong cài đặt và triển khai MySql Cluster ở đây. Hy vọng bạn đã thêm 1 chút kiến thức. Have a nice day!!!